Building an AI-Powered Medical Record
Summarization Platform With 88%
Accuracy
The Client
Headquartered in Santa Monica, California, the client is a leading tech startup revolutionizing the medico-legal space. They offer attorneys and law firms a platform for efficiently summarizing medical records, making crucial medical insights accessible and comprehensible for legal research.
Challenges

At the crossroads of legal and medical documentation, manual organization and extraction of information from vast medical records stood as a common barrier hindering efficiency and productivity.
Traditional approaches, like outsourcing or relying on an in-house team, proved time-consuming, expensive, and prone to inaccuracies. This process often stretched over days and incurred substantial costs, particularly for more extensive cases.
The client, with a background as an expert injury witness across various domains such as sports, workplace, motor vehicle, and aviation accidents, recognized the difficulty faced by medical and legal professionals when reviewing large volumes of medical records.
This necessitated a transition from the traditional and laborious method to a far more scalable approach, achieved by harnessing AI for the comprehensive analysis of extensive medical records.
The client initially collaborated with a Ukraine-based software company to bring their vision to life. However, after a dedicated three-year endeavor, they encountered challenges getting the product to market. Notably, limitations in the technology stack, such as the initial use of an older version of Kotlin for the backend, necessitated a refactoring into .NET to improve efficiency and scalability.
Identifying these gaps, the client sought a proficient software development company specializing in artificial intelligence with substantial experience in the medico-legal domain to launch their product successfully.
Why Maruti Techlabs?
By early 2022, the founders had invested three years in product development yet struggled to take it to market. Their major blockers were centered around the platform’s accuracy, scalability, and reliability, compounded by consistent delays in development. Also, a notable gap in communication from their previous team resulted in insufficient clarity regarding ongoing work on the engineering front.
To ensure a timely GTM (go-to-market) strategy, the client sought a technology partner that could build and deliver on the feature backlog while addressing their concerns related to platform accuracy, scalability, and reliability.
The client came across Maruti Techlabs on Clutch, a leading platform for finding business services. Our rich portfolio showcasing expertise in AI and ML captured their attention.
Upon receiving their inquiry, our sales team promptly engaged with the client to understand their business requirements and goals. During initial discussions, it became clear that the client sought a team with prior experience working on similar projects.
We showcased our experience building a medical letter classification model for a large-scale government entity based in the UK. This carried a degree of semblance to the solution the client sought. They found our work portfolio, client testimonials, and the fact that we had worked on building HIPAA-compliant platforms in the past very compelling.
Furthermore, our well-established processes, agile methodologies, and efficient project management practices ensure the precise alignment of our deliveries with their expectations.
Thus, Maruti Techlabs emerged as the ideal choice that seamlessly integrated skills, experience, and expertise to meet all the criteria on the client’s checklist.
Solution
Delving deep into the needs of the industry, we understood that our goal was to develop a pioneering AI-driven medical record summarization tool that could organize, categorize, and summarize thousands of diverse medical documents with high accuracy and speed.
Furthermore, considering that the client had already made advancements in the product development process, our role involved thoroughly analyzing the existing codebase. Our task was to identify gaps or shortcomings and strategically modify the system to launch a scalable and feature-rich Minimum Viable Product (MVP) as soon as possible.
Here’s a detailed roadmap of how our Maruti Techlabs team executed this project:
Phase 0: Three-week Audit Workshop
Collaborating closely with the client’s core team, we conducted a detailed three-week audit. This workshop involved key stakeholders, including our Chief Technical Architect, VP of Data Science and Technology, Head of DevOps, and Product Development Leads.
The audit thoroughly examined the project’s frontend, backend, and data service aspects, involving a detailed analysis of source code, architecture, cloud infrastructure, documentation, and processes. The four core standards that were a key part of this code audit were – maintainability, reliability, efficiency, and portability.
The primary goal was to deliver a comprehensive review, precisely defining our work scope. We outlined preferred methodologies and anticipated collaborative outcomes, ensuring transparency and alignment of expectations.
Here’s a high-level brief outlining what the audit encompassed –
- Examination of the current technology stack
- Software architecture assessment
- Code quality check
- Review of potential maintenance issues
- Technical documentation assessment
- Recommendations

Key insights from our Audit underscored several critical aspects:
- Data Science Model Performance: The performance and accuracy levels of data science models were concerning. The system took about 46 minutes to process 100 pages.
- Adherence to Software Development Practices: Consistency in following standard software development practices was lacking.
- Outdated Technology Stack: Performance and scalability issues were traced back to an outdated technology stack.
- Documentation: There was a lack of comprehensive documentation across the entire product (frontend, backend, Data Science). API versioning was also missing, which could lead to integration challenges in the future.
- Unit Test Cases: The absence of unit test cases highlighted the scope of improvement in early issue detection, code quality elevation, and streamlined QA efforts.
- Code Clean up: The need for clean-up of redundant, dead, or unused code surfaced, aiming to enhance code maintainability and overall system efficiency.
These insights were a foundation for our strategic approach to building the tool.
Phase 1 – Developing the AI Models
Adhering to the client’s demand for a versatile medical record summarization tool, we structured the project into a comprehensive suite of multiple AI models. We designed the AI models based on 4 stages of the workflow –
Stage 1 – Data Collection and Annotation
Stage 2 – Document Classification
Stage 3 – Data Extraction
Stage 4 – Summarization
Here’s an in-depth overview of the various stages of the workflow embedded in our AI medical record summarization tool:
- Stage 1 – Data Collection & Annotation
Document collection lies at the heart of a medical summarization tool. The diverse documents users submit are tagged, labeled, and annotated at this stage. This helps transform intricate medical records into well-organized sets, facilitating enhanced data accessibility.
We collaborated with the subject matter experts from the client’s team to define a tailored annotation protocol for the documents ranging from admission sheets and discharge summaries to physical therapy reports. The protocol plays a crucial role in labeling and organizing the data within the documents.
If the user submits a new document type not part of this predefined list, a new annotation protocol is tailored for that type. This adaptability ensures the tool can effectively handle various medical document types.

Several medical documents were annotated in the thousands and formed the basis of training data for the tool. To meet the client’s scalability and performance requirements, our team adopted node optimization, incorporating dynamic configuration decisions based on document size to enhance resource allocation and system efficiency.
The implementation of automatic image pulling on each node significantly reduced the overall wait time for document analysis and processing from 20 minutes to a mere 6 minutes.
- Stage 2 – Document Classification
Within a medical summarization tool, data classification plays a critical role in processing. It helps systematically categorize medical documents into specific types, such as admission sheets, laboratory reports, or discharge summaries.
In this model, the following categorizations occur –
- Document Type
We incorporated AWS Textract, XGBoost, and Bio-clinical Bert algorithms for document text embedding generation and classification. Bio-clinical Bert is a specialized language representation model for biomedical and clinical text. Pre-trained on extensive biomedical and clinical datasets, this model is further coupled with XGBoost to identify and process texts associated with medical documents.
The models extract the relevant elements and labels of the annotated documents and classify them as medical or non-medical. If the document type is non-medical, it is not processed. If the document type is marked as medical, it is tallied against the original list of document types and further processed.
- Handwritten Text
Handwritten clinical notes are vital for a patient’s medical history and treatment journey.
We tailored the Yolov5 algorithm to decipher the contents of each page. If more than 40% of the content on the page is handwritten, then the page is not considered for processing.
However, if the handwritten content is <40%, the algorithm extracts relevant elements from the page. It was further configured to ensure that signatures and overlay comments are not considered.
- Checkbox Mark Detection
The checkbox mark detection model is crucial in scanning medical forms to identify critical information such as the patient’s obesity status, diabetic condition, pregnancy status, and pre-existing diseases.
The Yolov5 algorithm was further leveraged here to automatically recognize and interpret the marked checkboxes on forms. This model helped rapidly and accurately retrieve essential information, providing a more comprehensive understanding of the patient’s health profile.
- Stage 3 – Data Extraction
Considering the end goal of generating medical summaries and outlining events chronologically, extracting critical medical information from patients’ healthcare records is fundamental for generating insightful medical summaries. These summaries must encompass comprehensive details related to diagnoses, prognoses, treatments, medical history, and more.
Leveraging Textract’s OCR capabilities facilitated the extraction of information, while Bio-Clinical Bert played a crucial role in highlighting critical insights within the extracted texts. We further utilized DistillBERT and LightGBM with TinyBert embedding for named entity recognition (patient name, doctor name, date, etc) and data classification

In response to the client’s emphasis on cost optimization and scalability, our data scientists implemented a caching mechanism in Textract. Furthermore, to enhance efficiency, the Textract Async API was employed to handle multiple requests concurrently, thereby reducing the API hit rate of paid services. This strategy met the client’s financial objectives and streamlined the process for diverse data extraction needs.
We leveraged a combination of AWS Comprehend Medical and ChatGPT for entity recognition and mapping connections between symptoms, diagnoses, treatments, and outcomes. This enabled a thorough extraction and relation mapping between different entities.
AWS Comprehend Medical is a natural language processing (NLP) service that Amazon Web Services (AWS) provides. It is designed to analyze and understand natural language text using machine learning algorithms.
AWS Comprehend Medical is primarily responsible for understanding medical entities like symptoms, diagnoses, treatments, and outcomes. The output from Comprehend is then passed onto ChatGPT for further refinement and extraction of ICD (International Classification of Diseases) / CPT (Current Procedural Terminology) codes. ICD codes are used for diagnosing and classifying health conditions, while CPT codes are used for describing medical procedures and services.
- Stage 4 – Chronological Order & Summarization
The final output is the chronological indexing with a structured timeline, facilitating efficient treatment progress tracking, pattern identification, and trend recognition.
The portal presents the summary through four distinct tabs, each encapsulating a unique medical record summary.
- Chronology and Timeline Summary
The final summary provides a detailed timeline of a patient’s medical history. This comprehensive overview helps us understand the progression of illnesses, treatments, and significant medical events over time. - Treatment Summaries
Treatment summaries offer a condensed overview of the therapeutic interventions a patient has undergone. It highlights critical medical procedures, medications, and their outcomes. - Diagnostic Summaries
Diagnostic summaries briefly summarize a patient’s diagnostic procedures, test results, and medical assessments. It offers a comprehensive snapshot of a patient’s health status. - Prognosis Summaries
Prognosis summaries encapsulate a patient’s anticipated health outcome based on their medical condition, treatment responses, and potential developments.

Each summary includes hyperlinks to the source documents, simplifying the retrieval of specific details and enabling the cross-checking of information. These links establish connections between related pieces of information, providing users with a comprehensive and holistic view of the patient’s health.
Through these models, the medical record summarization tool successfully condenses extensive medical records into concise and informative summaries while retaining critical details.
Phase 2: Custom Software Development
With precise client requirements and a detailed code audit, we established the architectural design and technology stack. We opted to break the architecture into microservices, not just for scalability and performance but the monolithic architecture was difficult to maintain, and it was challenging to add new features or fix the bugs. Any code change can have ripple effects. Moreover, the code is not validated by unit tests which makes it worse and more vulnerable to performing any changes. This was complemented by AWS hosting architecture featuring Kubernetes for robust infrastructure and streamlined deployment.
- Backend
Recognizing that the existing backend, initially built in Kotlin, was not leveraging the latest technology stack, we initiated a strategic refactoring process, transitioning to .NET Core. This shift provided an avenue to integrate modern technologies, frameworks, and tools, ensuring alignment with contemporary development standards. Parallely, the Data Science stack included Python, AsyncIO, PyTorch, XGBoost, YOLOv5, TinyBERT, Bio_ClinicalBERT, Pandas, Numpy and Boto3.
- Frontend
For frontend development, we selected React along with a blend of TypeScript and Flow, leveraging additional technologies such as Redux, Redux-Form, CSS-in-JS, Webpack, Yup, Vite.js, and SCSS. Recognizing the data-intensive nature of the project, we opted for Redis, ElasticSearch, and PostgreSQL as the foundation for our database.
- Team Structure
With these technical requisites at the forefront, we meticulously assembled a skilled team to spearhead the project to success. Our process adhered to three core principles:
- Past Collaboration: Developers who have worked together in the past foster a smoother team dynamic.
- Skills Match: Developers with precise skills matching the technical prerequisites needed to accomplish the project.
- Diverse Expertise: Team with varying experience levels, offering a well-rounded blend of senior and junior talent for a comprehensive perspective.
For the smooth execution of this project, we assembled a team of backend, frontend, QA, DevOps, BI, and Data Scientists. This team operated under the guidance of a technical project manager and technical lead, ensuring a well-coordinated and efficient workflow across the project lifecycle.
Phase 3: Portal Development
Leveraging the design wireframes as a foundation, our frontend team meticulously crafted a sophisticated portal. The portal enabled end-users to effortlessly –
- Upload extensive medical records,
- Streamline payment processing,
- Access patient information, and
- Receive intricately extracted medical summaries.

We introduced multiple purchase packages tailored to the document’s page count to enhance user flexibility. This feature was seamlessly integrated with Stripe, ensuring a smooth subscription process.
Following successful payment transactions, the portal efficiently guides end-users through uploading medical records in PDF format. These documents are then processed by a stream of AI models to extract, categorize, organize, and summarize medical records.
The resulting summary is thoughtfully organized into sections—meticulously detailing medical history, diagnosis, prognosis, treatments, and handwritten notes chronologically. This structuring ensures a clear and organized presentation of the patient’s journey. Users are offered the convenience of downloading the summaries in any predefined format, thus providing a user-centric experience.
Phase 4: Product Support
With the product being launched to a broader audience, it is critical to ensure that the right support mechanisms are in place.
We put together a product support team that works in a close capacity with the account manager on the client side. This strategic alignment ensures a tailored and continuous support experience, enhancing overall end-user satisfaction, gathering necessary feedback, and optimizing the product’s functionality.
This encompassed troubleshooting, guidance on tool usage, and prompt issue resolution, all delivered through an iterative approach that accommodated the evolving needs of end-users.
Understanding the Mechanism of Product Support

We used Jira to manage product support, with any issues logged via a customer-facing portal. Customers, as well as the client, can log a support ticket requesting bug fixes or improvements in the portal.
Here is a detailed overview of the product support mechanism –
- Support Ticket
The customer(s) or the account manager on the client side can log a support ticket reporting an issue. Our product support team takes on the tickets based on the severity level and pre-defined SLAs. - Diagnosis of the Issue
Our Product Support Agent works on diagnosing the issue and referring to solutions from the existing knowledge base. The agent parallely communicates with the customer or account manager for more information to better understand the challenges and associated root cause(s).
After this diagnosis, the agent precisely classifies the support ticket into an improvement or a bug. - Addressing an Improvement
If the support ticket diagnosis identifies an improvement, then the product support agent will pass on the relevant details to the Product Owner and the Technical Project Manager for further review. They would plan a user story for the same and incorporate it within the product roadmap. - Addressing a Bug
If the support ticket diagnosis identifies a bug, the product support agent would pass on the relevant details to the QA team, who would, in turn, file a bug, followed by the Product Owner prioritizing it within the sprint backlog.
Once the bug/story is completed, the ticket is closed, and the customer(s) or account manager on the client side will be notified of the same.
Thus, with a strategic focus on product support, Maruti Techlabs actively nurtured a positive user experience and played a pivotal role in sustaining the project’s success.
Phase 5 – HIPAA Compliance
To instill trust and foster widespread adoption, a product must rigorously adhere to the stringent regulations established by the Health Insurance Portability and Accountability Act (HIPAA).
Our team collaborated with an external audit agency to meticulously formulate a concise HIPAA compliance implementation plan. This strategic initiative aimed to navigate the intricate landscape of healthcare regulations. The external agency played a crucial role in identifying potential system vulnerabilities and areas for enhancement.
Subsequently, a comprehensive checklist was developed, encompassing tasks, policies, and procedures. Our team implemented integrated security measures, including data encryption, backup protocols, and role-based access control. Additionally, efforts were directed toward educating employees and team members on HIPAA, underscoring privacy and security as core priorities.
To fortify our commitment to compliance, Business Associate Agreements (BAAs) were executed with all third-party vendors and partners. Detailed records covered compliance efforts, training initiatives, and assessments, ensuring a comprehensive approach.
Upon completing the Minimum Viable Product (MVP) for the Beta launch, the platform underwent a rigorous audit and continuous monitoring by an external agency. This proactive approach to control monitoring ensures robust compliance, providing full visibility into the compliance status at all times.
Turn your digital data into
informed decisions. With
Computer Vision.



Don't take our word for it, take theirs!



Communication and Collaboration
Our collaboration with the client’s team was seamlessly facilitated through a suite of communication channels. Jira, a robust project management tool, was central to streamlining and organizing project-related tasks. Simultaneously, Slack served as a dynamic platform for day-to-day communication, providing a quick and interactive channel for ongoing discussions.
To ensure the smooth execution of the project, our development team embraced the agile methodology, emphasizing software delivery efficiency and adaptability to dynamic client needs. Implementing a 2-week sprint cycle became a cornerstone, allowing collaborative task definition at the onset of each sprint and incremental progress toward predefined goals. This agile approach fostered continuous feedback loops and approvals, maintaining alignment between project expectations and execution.
Thus, we successfully established a structured collaboration framework that facilitated meticulous project management and cultivated clear communication, enabling timely responses and sustaining project momentum throughout the development process.
Technology Stack

Result
- Developed and scaled 10 Data Science models from 33% accuracy to an impressive accuracy rate of 88%, enhancing the platform’s analytical capabilities.
- Enhanced the overall processing capability of the platform from 200 pages/hour to 12,000 pages/hour.
- Successfully launched the product within 10 months of project initiation, overcoming challenges that had persisted for 3 years.
- Executed all work strictly adhering to HIPAA standards and regulations, ensuring data security and privacy. The platform underwent a third-party audit for HIPAA compliance before launching.
Maruti Techlabs successfully delivered a product that not only met but surpassed client expectations by aligning with their objectives, comprehensively understanding their brand, and leveraging high-quality development skills. The platform trained on millions of data points, a product of this collaboration, can effectively analyze thousands of medical records, extract patient information, organize patient history chronologically, categorize details about diagnoses, prognoses, treatment, etc., and generate concise summaries with high accuracy and speed.
The achievement in this project underscores the significance of flexibility, in-depth comprehension of client requirements, and possessing robust technical capabilities. Our proven product development expertise, flexible approach, and unwavering commitment to innovation have played a pivotal role in shaping the product. This strategic involvement has driven success and fostered digital transformation within the medico-legal space.
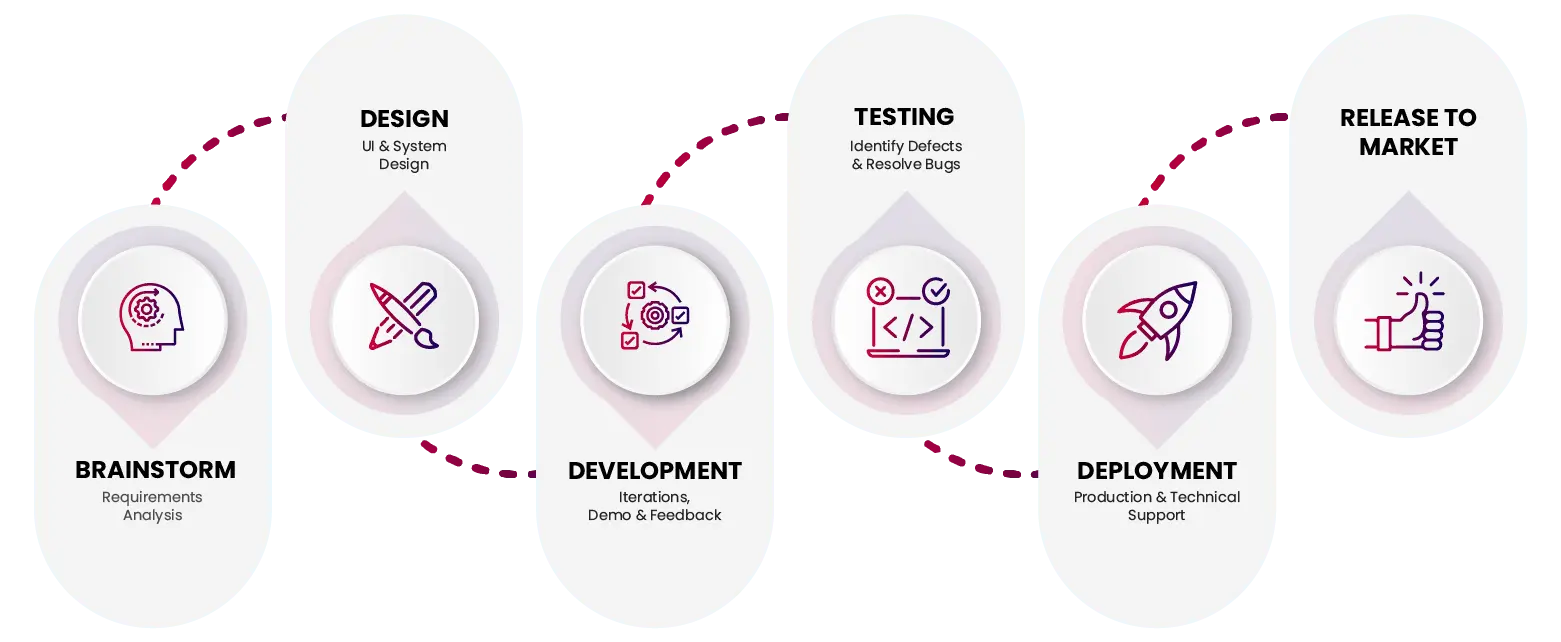
Our Development Process
We follow Agile, Lean, & DevOps best practices to create a superior prototype that brings your users’ ideas to fruition through collaboration & rapid execution. Our top priority is quick reaction time & accessibility.
We really want to be your extended team, so apart from the regular meetings, you can be sure that each of our team members is one phone call, email, or message away.





Trusted By:








